Adversarial Examples in Computer Vision
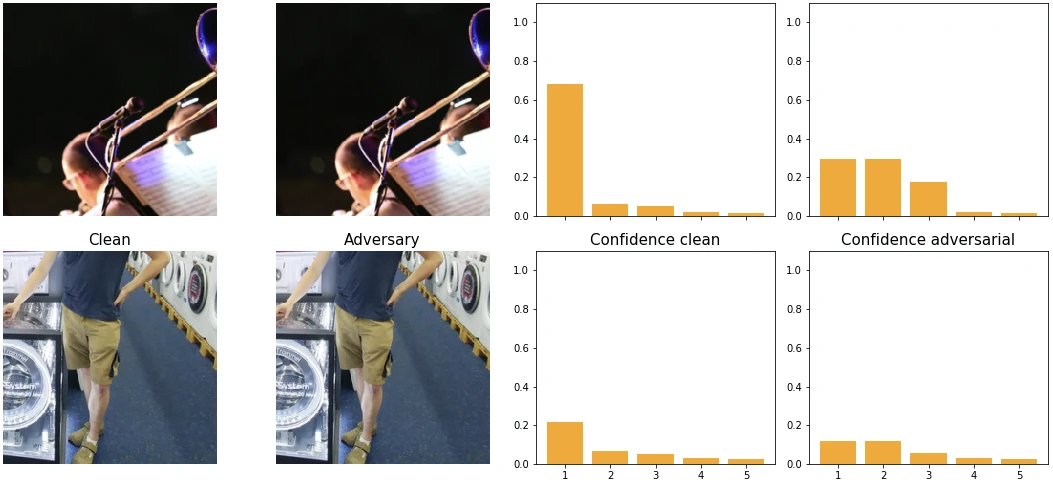
Explored how subtle, imperceptible image changes can mislead machine learning models, and developed practical attack implementations to understand model vulnerabilities.
The Challenge
In the field of computer vision, a surprising vulnerability exists: machine learning models can be entirely misled by tiny, imperceptible alterations to an image. These "adversarial examples" are not just a security concern; they offer crucial insights into how neural networks learn and the inherent limitations of their learned representations. Understanding this phenomenon is vital for building robust and reliable AI systems, as it reveals that vision models often perceive the world in ways fundamentally different from humans.
My Solution
To understand this complex challenge, my project involved a comprehensive review of leading research in adversarial examples, focusing on the state of the art in 2020. More importantly, to move beyond theory, I implemented selected attack methods from these papers in practical Jupyter notebooks. This hands-on approach allowed me to deeply explore how these perturbations work, providing a clear, step-by-step explanation of their mechanics. Through these implementations, I aimed to demystify the process and make the underlying principles accessible.
The Outcome
Deeper understanding of AI vulnerabilities: Gained firsthand insight into the fragility of deep learning models and the critical need for robust AI design.
Practical application of theoretical research: Translated complex academic concepts into working code, demonstrating the ability to bridge theory and practice.
Insights into model behavior: The project offered valuable insights into the feature representations learned by neural networks and the limitations of their internal logic.
Contribution to knowledge sharing: Presented the state of the art and practical implementations, aiding others in understanding this crucial area of AI safety and interpretability.