Comprehensive NLP Model & RAG System Evaluation
A deep dive into evaluating Natural Language Processing (NLP) models, with a specialized focus on Retrieval-Augmented Generation (RAG) systems. Explores foundational metrics, common failure modes, advanced evaluation frameworks, and strategies to overcome the data bottleneck.
The Challenge
The proliferation of advanced NLP models, particularly Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) systems, has made robust and reliable evaluation more critical than ever. Developers and researchers face a multifaceted challenge:
- Navigating Complex Metrics: Understanding which metrics apply to different NLP tasks (classification, sequence-to-sequence, generation, QA) and how they accurately reflect model performance.
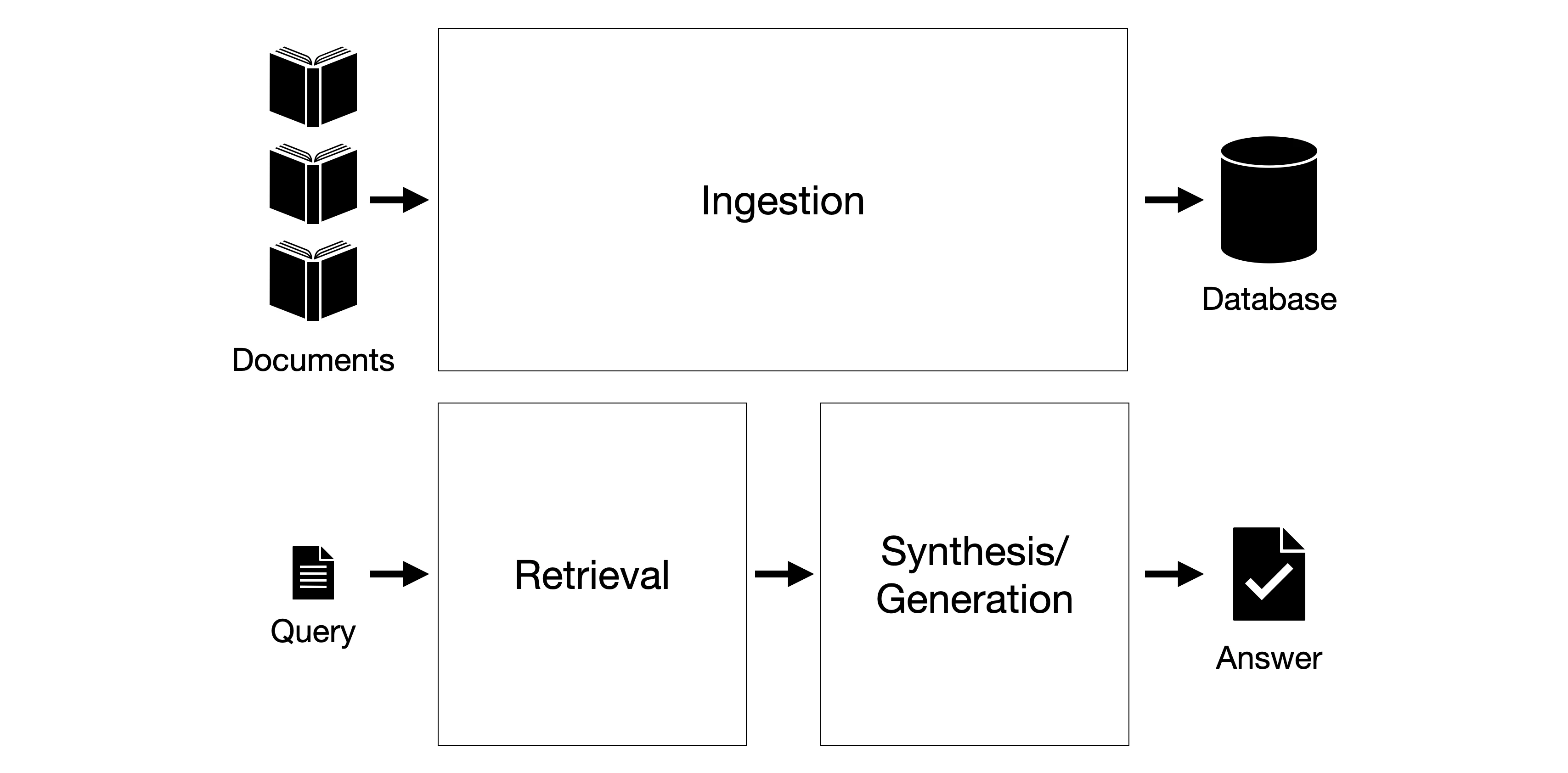
- Identifying Failure Modes: Pinpointing where and why RAG pipelines can fail. From data ingestion and retrieval to synthesis, including issues like hallucinations, distractors, and lack of coherence.
- Overcoming Data Bottlenecks: The reliance on extensive human-labeled datasets for evaluation, which is time-consuming, costly, and often impractical for real-world RAG applications.
A comprehensive, practical guide was needed to demystify these challenges and provide actionable insights for building trustworthy NLP systems.
My Solution
I authored an in-depth series of blog posts and developed associated code examples focused on comprehensive NLP model evaluation, with a specialized emphasis on RAG systems. This project systematically addresses the evaluation landscape:
Foundational Metrics: I explored core evaluation metrics for various NLP tasks (text classification, sequence-to-sequence, language modeling, text generation, question answering), explaining their nuances (e.g., Accuracy, Precision, Recall, F1, BLEU, ROUGE, Perplexity, EM).
RAG-Specific Evaluation: I provided detailed insights into common RAG failure modes across ingestion, retrieval, and generation stages (e.g., irrelevant data, poor embeddings, hallucinations, context relevance). This built the foundation for introducing specific metrics for Retrieval Evaluation (Precision@k, Recall@k, F1@k, MRR, MAP, DCG, NDCG) and Generation Evaluation (Faithfulness, Answer Relevance, Context Relevance).
Addressing Data Bottlenecks: Crucially, I explored modern approaches and frameworks like RAGAs and ARES that leverage LLMs to generate synthetic evaluation data, significantly reducing the reliance on costly human-labeled datasets. This section demonstrates how to achieve scalable and practical evaluation.
Practical Implementation: Throughout the series, I provided conceptual understanding alongside practical examples and code implementations (e.g., custom BLEU score, experiments repo), enabling readers to apply these concepts directly.
My solution aimed to provide a structured, accessible, and actionable resource for anyone looking to build, evaluate, and optimize high-performing NLP and RAG systems.
The Outcome
Demystified Complex Evaluation: Created a highly valued resource that simplifies the intricate landscape of NLP and RAG model evaluation for developers, researchers, and practitioners.
Enhanced System Reliability: Provided actionable strategies and metrics for identifying, understanding, and mitigating critical failure modes in RAG pipelines, leading to more robust and trustworthy AI applications.
Addressed Industry Challenges: Offered practical solutions to the data bottleneck in evaluation by exploring modern, automated frameworks, enabling more scalable and efficient continuous improvement of LLM systems.
Showcased Deep Expertise: Demonstrated comprehensive expertise in advanced NLP concepts, LLM architectures, evaluation methodologies, and the practical application of machine learning for real-world problem-solving.
Contributed to Community Knowledge: Provided a publicly accessible, in-depth guide that helps advance the understanding and best practices for NLP and RAG evaluation.
Further Reading (Individual Post Links)
-
Understanding the BLEU Score for Translation Model Evaluation
-
Building Baseline RAG Pipelines with OpenAI and LLAMA 3 8B from Scratch
-
Understanding Failures and Mitigation Strategies in RAG Pipelines
-
Metrics for Evaluation of Retrieval in Retrieval-Augmented Generation (RAG) Systems
-
Beyond Traditional Metrics - Evaluating the Generation Stage of RAG Systems